

An Introduction to Genetic Algorithms: The Concept of Biological Evolution in Optimization#
Genetic algorithms (GA) are inspired by the natural selection of species and belong to a broader class of algorithms referred to as Evolutionary Algorithms (EA). The concept of biological evolution is used to solve all different kinds of problems and has become well-known for its reliable global search capabilities. Thus, genetic algorithms have been used to solve myriads of real-world optimization problems and are an essential subject of research in optimization and related fields. They are known for their multidisciplinary usage across disciplines such as natural, social, and earth sciences, finance, or economics. Furthermore, genetic algorithms have been commonly employed to address well-known optimization problems in Data Science, Machine Learning, and Artificial Intelligence, for instance, selecting features in a data set, recognizing patterns, or determining the architecture of neural networks.
After having used genetic algorithms for more than ten years, I still find the concept fascinating and compelling. This article aims to provide you an introduction into genetic algorithms and the usage of evolutionary operators. The theory of genetic algorithms is described, and source code solving a numerical test problem is provided. Developing a genetic algorithm by yourself gives you a deeper understanding of evolution in the context of optimization. If you have always been curious about genetic algorithms but have never found the time to implement one, you should continue reading. Moreover, if you are as passionate as I am about the concept of evolutionary computation and eager to learn more about sophisticated ideas, feel free to sign up for the waiting list of my online course.
Genetic Algorithms are inspired by Charles Darwin’s theory: “Natural selection is survival of the fittest”. The term fit refers to the success of reproduction or, in other words, the capability of creating offsprings for successive generations. Reproductive success reflects how well an organism is adapted to its environment. Thus, the two core components of genetic algorithms are the i) mating (or reproduction) and the ii) survival (or environment selection). The goal of using the concept of biological evolution in the context of optimization is to define meaningful recombination and survival operators and let evolution occur.
Before I start to explain the algorithm’s outline, I would like to talk about the terminology in evolutionary computing. Most genetic algorithms do not use a single solution, but a solution set referred to as population in the context of evolutionary computation. The size of the population is predefined beforehand and referred to as population size. Each solution in the population is usually called an individual|. Moreover, an individual resulting from the recombination of two or more parent individuals is known as an offspring. Each iteration of a genetic algorithm consisting of mating and survival is called generation. Understanding the evolutionary computation’s terminology helps follow the ideas presented in this article and, in general, in the literature.
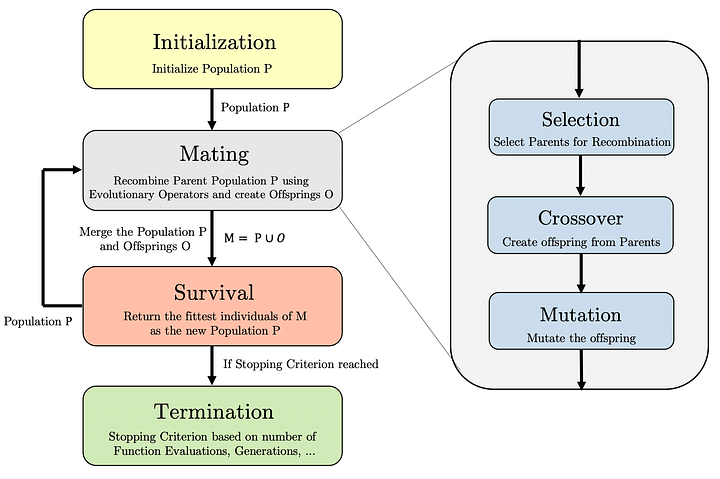
A genetic algorithm starts with initializing individuals forming the population P of a predefined size |P|. The population P undergoes the process of mating, which has the goal of producing offsprings O through recombination. To generate offsprings through mating, the population has to go through parental selection, crossover, and mutation. Then, the population P and offsprings O are merged to the solution set M of size |P+O|. The survival reduces M again to a solution set of size |P| by selecting only the fittest individuals. The resulting truncated population is then used for recombination in the next generation. This process is repeated until the termination criterion is met.
If you are more a pseudo-code kind of person, the following description might look even more appealing to you:
Define pop_size, n_gen;
P = initialize(pop_size)
evaluate(P)
for k in (1, .., n_gen)
parents = selection(P)
O = mutation(crossover(parents))
evaluate(O)
M = merge(P, O)
P = survival(M)
endfor
Our final implementation will look very similar to this pseudo-code. By looking at this description more carefully, we can notice that the following functions have to be implemented:
Evaluate: The actual problem to be solved, where the function determines the fitness of each individual.
Initialize: This method returns the initial population P.
Selection: A function returning the individuals in the population functioning as parents for recombination.
Crossover: A function creating one or multiple offsprings given two or more parents.
Mutation: A method mutation each offspring with a specific probability.
Survival: A function reducing the merged population to a set of solutions equal to the population size by applying the principle of survival of the fittest.
That looks like a lot. Don’t be intimidated, though. I will guide you through implementing each of the methods. Some of them are only one or two lines of code and rather simple in our case. However, each of them has a specific purpose and can be customized to your optimization problem.
Before I start describing a numerical optimization problem to demonstrate the usage of genetic algorithms, I would like to say a few words about what you have seen so far. I am not sure about you, but when I came in touch with genetic algorithms for the first time, the whole concept sounded like a somewhat mystical thing to me. I could not imagine how applying the principle of evolution can help me actually to solve my optimization problem. Nevertheless, implementing my first genetic algorithm to solve an optimization problem I was facing during that time truly opened my eyes and made me want to know more about evolutionary computation and related concepts. Finally, I also to pursue a Ph.D. in this fascinating research field and combining my fascination with my everyday work. To share a bit of this experience, we will solve a numerical problem using a genetic algorithm. With we, I mean we. I truly encourage you to open an editor or IDE of your choice and follow the steps along this journey we are going to take in this article.
Problem Definition#
Why is it so important to actually look at a specific optimization problem and to solve it? My answer to that question might be a bit more of a personal nature. Whenever I encounter something knew and I really want to understand it, I follow the steps: read, understand and apply. And applying for me often means implementing it. You won’t belief how often I had the impression of understanding a concept but was not even close being able to develop the code for it. Moreover, I am a person who likes to see things in practice. When I have started to learn coding, I thought I am going to read a book from beginning to end and I am able to code. Whoever has tried the same knows this is fundamentally wrong. Coding requires using the theory in practice. Long story short, this article develops the algorithm based on a numerical problem to not only talk about the benefits of genetic algorithms but actually let you experience them by yourself.
The following optimization problems shall be solved:
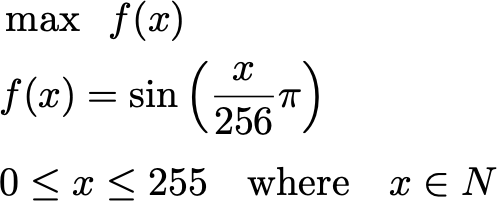
In this optimization problem, we consider the sine function with the integer-valued variable x ranging from 0 to 255. As most of you might (and probably really should know), the sine function has a maximum at π/2 considering the range from (0, 2π). With the range of x (which is only mapped to the sine function in range (0, π)) and x being divided by 256, the analytically derived maximum lies at x=128.
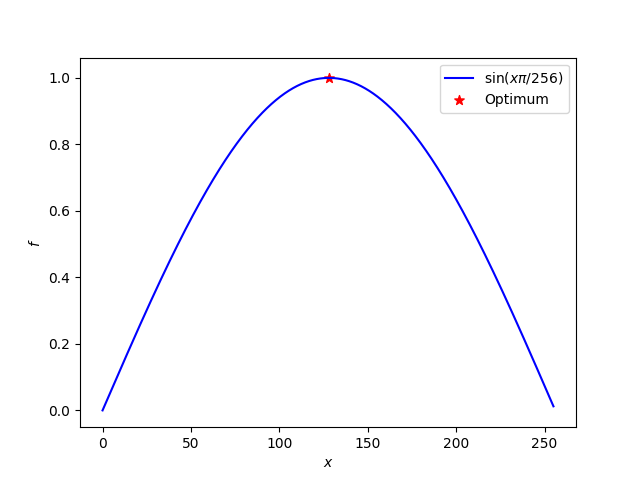
Because genetic algorithms operate on binary variables (no worries, the concept is generalizable to any variable type), we consider an 8-bit binary variable. If you haven’t been confronted with binary variables and the conversion of them to decimal values, tons of tutorials and converters can be found online. The illustration below shows you how the binary number 11001001 is converted to its decimal correspondent 201.
And luckily, the conversion of eight bits to decimals directly falls into the range from 0 to 255, which is the defined range of the variable x. If you assume I have constructed the test problem to match precisely this encoding, you might not be wrong (of course, if this shall not be the case for your problems, there are other ways to deal with it). The fitness function’s optimum in the decimal search space 128 is equal to 10000000 in the binary encoding. Thus, this is the binary string with the largest fitness value that can be obtained.
Let us start implementing the fitness function to be used in the genetic algorithm. The evaluate function takes a one-dimensional binary-valued array of length 8. The value is converted to an integer and then plugged in into the equation.
import numpy as np
def evaluate(x):
to_int = (x * [128, 64, 32, 16, 8, 4, 2, 1]).sum()
return np.sin(to_int / 256 * np.pi)
Genetic Algorithm#
The power of genetic algorithms is the principle that can be applied to many different optimization problems. This flexibility comes with the burden of defining evolutionary operators for your concrete optimization problem. Fortunately, for common types of optimization problems, this has already been done and can be used. Reading this, you might already suspect this might have been the reason why I have converted the problem to have binary variables. Let us start now to define each of the operators to construct the genetic algorithm finally.
Initialization#
In the beginning, the initial population needs to be created. In practice, this might incorporate some domain knowledge of experts and or already introduce some bias towards more promising solutions. In our case, we keep things simple.

We treat our problem as a black-box optimization problem where no domain-specific information is known beforehand. Thus, our best bet is to initialize the population randomly or, in other words, to create individuals as random sequences of zeros and ones. The initialize method shown below takes care of that and returns a random binary array of length 8.
def initialize():
return np.random.choice([0, 1], size=8)
Selection#
After the initialization of the population, individuals are selected from the population are selected to participate in mating. In this article, we are going to implement a random selection of parents for reproduction. A random selection is a basic implementation; however, it is worth noting that enhanced selection procedures exist and are usually used in practice. Commonly used, more sophisticated selection strategies are incorporating so-called selection pressure by letting individuals already compete with each other during the selection in a tournament or restricting the selection to the neighborhood of solutions. For this rather simple test problem, the random selection shall be sufficient.
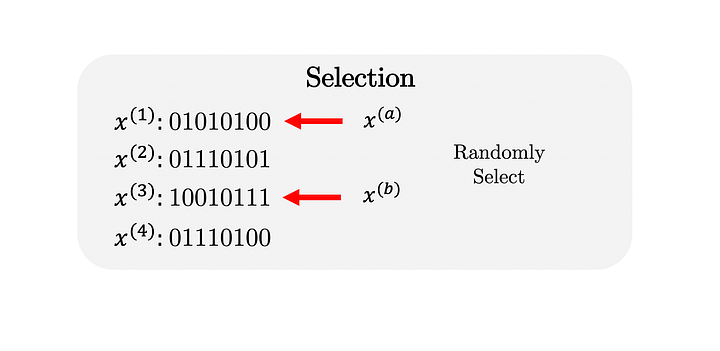
More concrete, the select method needs to know how many matings the algorithm will perform and how many parents are necessary for each recombination. Because we are randomly selecting the parents, we can make use of the randint function and only need to pass the corresponding shape. The result is a two-dimensional integer-valued matrix where each row represents a mating and each column an individual which represents a parent.
def select(n_matings, n_parents):
return np.random.randint(0, n_matings, (n_matings, n_parents))
Crossover#
After having selected the parents, the recombination takes place. The crossover produces offsprings given at least two parent individuals. We will implement Uniform Crossover (UX), which takes two parents and returns one offspring. The offspring inherits with uniform probability from the first or second parent’s value for each position. The uniform probability distribution implies that, on average, across all individuals, four values from the first and four values from the second parent will exist in the offspring (this is not necessarily the case for each offspring).
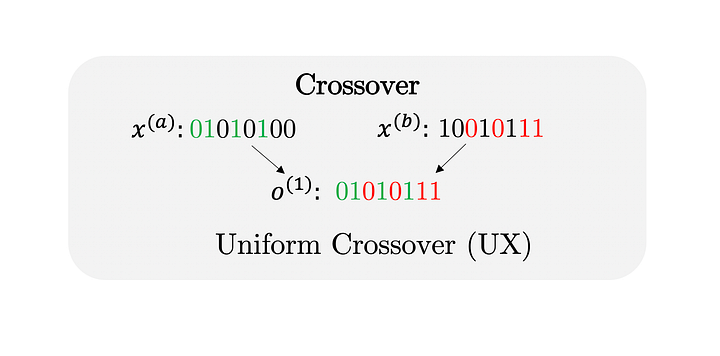
The crossover function performs the reproduction given the two arrays representing the parents (parent_a and parent_b). The random value in rnd determines whether the values from the first or second parent are used. Depending on rnd the corresponding values are set to the offspring, which is finally returned by the method.
def crossover(parent_a, parent_b):
rnd = np.random.choice([False, True], size=8)
offspring = np.empty(8, dtype=np.bool)
offspring[rnd] = parent_a[rnd]
offspring[~rnd] = parent_b[~rnd]
return offspring
Mutation#
Genetic variations can arise from recombination and gene mutations. The latter principle is also transferred to genetic algorithms by applying a mutation operator on the offspring created by the crossover. For binary variables, Bitflip Mutation (BM) is often used practice. As the name already says, the mutation flips an existing but in the gene with a predefined probability. In our implementation, we perform a flipping of a bit with a probability of 1/8=0.125.

The function mutate gets the resulting offspring of the crossover and returns the mutated individual. The probability for a bitflip is considered by creating first a uniformly random real-valued array rnd and then choosing bits to flip if the corresponding number is less than a threshold value of 0.125.
def mutate(o):
rnd = np.random.random(8) < 0.125
mut = o.copy()
mut[rnd] = ~mut[rnd]
return mut
Survival#
Puhhhhhh. Everything so far was already a lot to digest. I promise there is only one more module to implement before we can put everything together. The survival implementation needs to imitate the natural selection and let the fittest individuals survive. In our case, the fitness corresponds directly to the function value returned by the function. Thus, after merging the parent and offspring population, the survival does nothing else than sorting the individuals by their function values and letting the best individuals survive until the population size is reached.

Merging the two populations is usually already done in the main loop of the algorithm. Thus, the survival method retrieves directly the function values f of the merged population of which n_survivors (usually equal to the population size) individuals need to be selected. The individual selection is achieved by sorting the function values accordingly and truncating the sorted list using the [:index] notation. Note that the function values are sorted ascending and, thus, to maximize
the function, the sorting needs to be regarding -f .
def survival(f, n_survivors):
return np.argsort(-f)[:n_survivors]
Moreover, in practice, there is one more critical issue to consider. And this is duplicate elimination. For genetic algorithms to be efficient, it is fundamentally important to ensure diversity in the population. In order to ensure diversity, each genome shall exist at most once in the population. Thus, we have to take care of possible duplicates after merging the population and offsprings. No worries if you do not understand the following method’s details; however, keep in mind ensuring diversity and eliminating duplicates is critical.
from scipy.spatial.distance import cdist
def eliminate_duplicates(X):
D = cdist(X, X)
D[np.triu_indices(len(X))] = np.inf
return np.all(D > 1e-32, axis=1)
The implementation of elimininate_duplicate uses the cdist function, which calculates all pairwise distances D. The pairwise distance being zero indicates two genomes are identical. Since we would like to keep one of the duplicates, the upper triangular matrix of D is filled with np.inf before checking individual (row) is significantly different compared to others.
Algorithm#
Finally, you made it this far already. Now we are ready to implement the main loop of a genetic algorithm. Before we start, we have to define two parameters: The population size pop_size and the number of generations n_gen . Both can be challenging to determine in practice. For some more challenging problems, a larger population size (>100) might be required to avoid preliminary convergence. The number of iterations can be replaced by checking how much progress has been made recently in
each generation. However, this shall, for this illustrative example, not be of interest. We have set pop_size=5 and n_gen=15, which already is sufficient to solve the optimization problem.
pop_size = 5
n_gen = 15
# fix random seed
np.random.seed(1)
# initialization
X = np.array([initialize() for _ in range(pop_size)])
F = np.array([evaluate(x) for x in X])
# for each generation execute the loop until termination
for k in range(n_gen):
# select parents for the mating
parents = select(pop_size, 2)
# mating consisting of crossover and mutation
_X = np.array([mutate(crossover(X[a], X[b])) for a, b in parents])
_F = np.array([evaluate(x) for x in _X])
# merge the population and offsprings
X, F = np.row_stack([X, _X]), np.concatenate([F, _F])
# perform a duplicate elimination regarding the x values
I = eliminate_duplicates(X)
X, F = X[I], F[I]
# follow the survival of the fittest principle
I = survival(F, pop_size)
X, F = X[I], F[I]
# print the best result each generation
print(k+1, F[0], X[0].astype(np.int))
Running the code results in the following:
1 0.9951847266721969 [1 0 0 0 1 0 0 0]
2 0.9951847266721969 [1 0 0 0 1 0 0 0]
3 0.9951847266721969 [1 0 0 0 1 0 0 0]
4 0.9951847266721969 [1 0 0 0 1 0 0 0]
5 0.9951847266721969 [1 0 0 0 1 0 0 0]
6 0.9996988186962042 [1 0 0 0 0 0 1 0]
7 0.9996988186962042 [1 0 0 0 0 0 1 0]
8 0.9996988186962042 [1 0 0 0 0 0 1 0]
9 0.9996988186962042 [1 0 0 0 0 0 1 0]
10 0.9996988186962042 [1 0 0 0 0 0 1 0]
11 0.9996988186962042 [1 0 0 0 0 0 1 0]
12 0.9999247018391445 [1 0 0 0 0 0 0 1]
13 1.0 [1 0 0 0 0 0 0 0]
14 1.0 [1 0 0 0 0 0 0 0]
15 1.0 [1 0 0 0 0 0 0 0]
Yessssssssss. The genetic algorithm has found the optimum of our numerical test problem. Isn’t this amazing? The algorithm did not know anything about our problem and yet was able to converge to the optimum. The only thing we have done is we have defined a binary encoding, suitable operators and a fitness function. The evolution has figured out a way to find a solution which matches with the optimum we have derived analytically before. For real-world problems you might not even know the optimum and might be amazed what solutions your genetic algorithm is able to come up with. I hope you are fascinated as much as I am. I hope you already imagine how to apply biological evolution concept to optimization problems you might be facing in the future.
Do not reinvent the wheel, use a framework#
Coding everything up by yourself is useful because it helps to understand each of the evolutionary operators’ roles. However, you probably don’t want to write the same code on and on again. For this purpose, I have written a framework called pymoo, which focuses on evolutionary optimization. To be more precise on evolutionary multi-objective optimization, which is an even more generalized concept. In the following, I will show you how to code up this example in pymoo.

First, the problem needs to be defined. Our problem has eight variables ( n_var=8 ), one objective ( n_obj=1 ) and no constraints ( n_constr=0 ). Then, the _evaluate function is overwritten to set objective values. Note that most optimization frameworks consider only minimization (or only maximization) problems. Thus, the problem needs to be converted to one or the other by multiplying the fitness function by -1. Since pymoo considers minimization, the fitness function has a
minus sign before the value is assigned. After defining the problem, the algorithm object GA is initialized, and the evolutionary operators (which are already available in the framework) are passed. In this article, we have implemented several operators and have learned their specific role in a genetic algorithm. Finally, the problem and algorithm objects are passed to the minimize method, and the optimization is started.
import numpy as np
from pymoo.algorithms.soo.nonconvex.ga import GA
from pymoo.core.problem import Problem
from pymoo.factory import get_sampling, get_crossover, get_mutation
from pymoo.optimize import minimize
class MyProblem(Problem):
def __init__(self):
super().__init__(n_var=8,
n_obj=1,
n_constr=0,
elementwise_evaluation=True)
def _evaluate(self, x, out, *args, **kwargs):
to_int = (x * [128, 64, 32, 16, 8, 4, 2, 1]).sum()
out["F"] = - np.sin(to_int / 256 * np.pi)
problem = MyProblem()
algorithm = GA(
pop_size=10,
sampling=get_sampling("bin_random"),
crossover=get_crossover("bin_ux"),
mutation=get_mutation("bin_bitflip"))
res = minimize(problem,
algorithm,
("n_gen", 10),
seed=1,
verbose=True)
print("X", res.X.astype(np.int))
print("F", - res.F[0])
The results are shown below:
=============================================
n_gen | n_eval | fopt | favg
=============================================
1 | 10 | -9.99925E-01 | -6.63021E-01
2 | 20 | -9.99925E-01 | -8.89916E-01
3 | 30 | -9.99925E-01 | -9.57400E-01
4 | 40 | -1.00000E+00 | -9.88849E-01
5 | 50 | -1.00000E+00 | -9.91903E-01
6 | 60 | -1.00000E+00 | -9.95706E-01
7 | 70 | -1.00000E+00 | -9.96946E-01
8 | 80 | -1.00000E+00 | -9.97585E-01
9 | 90 | -1.00000E+00 | -9.97585E-01
10 | 100 | -1.00000E+00 | -9.97585E-01
X 1
F 1.0
Same result. Less code. Using a framework helps you focus on the most important things to solve your problem. If you like pymoo and want to support further development, please give us a like on Github or contribute to it by sending a pull request.
Want More?#
I genuinely hope you have enjoyed coding a genetic algorithm by yourself. You have mastered the basics of genetic algorithms, but trust me, there are many more things to learn. Genetic algorithms are not a single algorithm but an algorithmic framework. Having such flexibility is excellent, but designing and applying evolutionary operators on your optimization problems can be challenging.
I am currently creating an online course that shows the secrets of genetic algorithms in a hands-on manner (similarly to this article). It not only teaches you the theory of biological evolution but also lets you implement various kinds of genetic algorithms to tackle a diversity of optimization problems you might be facing. In this article, I have covered for illustration purpose an optimization problem with binary variables. However, the concept of evolution works on all kinds of data structures such as floats, integers, or even trees. Having such a skillset makes you an optimization expert and lets you see optimization with different eyes.

If you like to be notified when I have released my course, you should sign up on the waiting list.
Source Code#
import numpy as np
from scipy.spatial.distance import cdist
def evaluate(x):
to_int = (x * [128, 64, 32, 16, 8, 4, 2, 1]).sum()
return np.sin(to_int / 256 * np.pi)
def initialize():
return np.random.choice([0, 1], size=8)
def select(n_matings, n_parents):
return np.random.randint(0, n_matings, (n_matings, n_parents))
def crossover(parent_a, parent_b):
rnd = np.random.choice([False, True], size=8)
offspring = np.empty(8, dtype=np.bool)
offspring[rnd] = parent_a[rnd]
offspring[~rnd] = parent_b[~rnd]
return offspring
def mutate(o):
rnd = np.random.random(8) < 0.125
mut = o.copy()
mut[rnd] = ~mut[rnd]
return mut
def eliminate_duplicates(X):
D = cdist(X, X)
D[np.triu_indices(len(X))] = np.inf
return np.all(D > 1e-32, axis=1)
def survival(f, n_survivors):
return np.argsort(-f)[:n_survivors]
pop_size = 5
n_gen = 15
# fix random seed
np.random.seed(1)
# initialization
X = np.array([initialize() for _ in range(pop_size)])
F = np.array([evaluate(x) for x in X])
# for each generation execute the loop until termination
for k in range(n_gen):
# select parents for the mating
parents = select(pop_size, 2)
# mating consisting of crossover and mutation
_X = np.array([mutate(crossover(X[a], X[b])) for a, b in parents])
_F = np.array([evaluate(x) for x in _X])
# merge the population and offsprings
X, F = np.row_stack([X, _X]), np.concatenate([F, _F])
# perform a duplicate elimination regarding the x values
I = eliminate_duplicates(X)
X, F = X[I], F[I]
# follow the survival of the fittest principle
I = survival(F, pop_size)
X, F = X[I], F[I]
# print the best result each generation
print(k + 1, F[0], X[0].astype(np.int))